
汇编入门log(二)
学习汇编的第二天
寻址模式
大多数汇编语言指令都需要处理操作数,其中操作数地址提供了存储要处理的数据的位置。
对应的三种基本寻址模式,分别是
- 寄存器寻址
- 立即寻址
- 内存寻址
寄存器寻址
在此寻址模式下,寄存器包含操作数。例如:
1 | MOV DX, TAX_RATE ; Register in first operand |
由于在寄存器之间处理数据不涉及内存,因此它提供了最快的数据处理速度。
立即寻址
立即操作数具有常量值或表达式。例如:
1 | BYTE_VALUE DB 150 ; A byte value is defined |
内存寻址
当操作数以内存须知方式指定时,需要直接访问内存,通常是数据段。这种寻址方式会导致数据处理熟读变慢。为了定位内存中数据的准确位置,我们需要段起始地址(通常在DS寄存器中找到)和偏移值。该偏移值也称为有效地址。
在内存中寻址,具体也有三个方法:
- 直接内存寻址
- 直接偏移寻址
- 间接内存寻址
直接内存寻址
在直接内存寻址模式下,偏移值直接指定为指令的一部分,通常由变量名指示。汇编器计算偏移值并维护一个符号表,其中存储了程序中使用的所有变量的偏移值。
在直接内存寻址中,一个操作数引用内存位置,另一个操作数引用寄存器。
例如:
1 | ADD BYTE_VALUE, DL ; Adds the register in the memory location |
直接偏移寻址
在直接偏移寻址模式使用算术运算符来修改地址。如果有C语言基础的话,可以理解为数组。
例如,查看以下定义数据表的定义
1 | BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes |
以下操作将内存中的表中的数据访问到寄存器中
1 | MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE |
间接内存寻址
间接内存寻址模式利用计算机的偏移寻址能力。通常,基址寄存器 EBX、EBP(或 BX、BP)和索引寄存器(DI、SI)被编码在方括号内用于存储器引用,用于此目的。
间接寻址通常用于包含多个元素的变量,例如数组。 数组的起始地址存储在 EBX 寄存器中。
以下代码片段显示了如何访问变量的不同元素。
1 | MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0 |
MOV
用于将数据从一个存储空间移动到另一个存储空间。
语法为
1 | MOV destination, source |
变量
NASM提供了各种define指令来为变量保留存储空间,
定义汇编指令用于分配存储存储空间,可保留和初始化一个或多个字节。
为初始化数据分配存储空间
初始化数据的语法为
1 | [variable-name] define-directive initial-value [,initial-value]... |
其中,variable-name是每个存储空间的标识符。
define指令的物种基本形式为:
| 指令 | 用途 | 存储空间 |
|---|---|---|
| DB | 定义Byte | 分配1个字节 |
| DW | 定义Word | 分配2个字节 |
| DD | 定义Doubleword | 分配4个字节 |
| DQ | 定义Quadword | 分配8个字节 |
| DT | 定义十个字节 | 分配10个字节 |
例如:
1 | choice DB 'y' |
需要注意:
- 字符的每个字节都以其十六进制的 ASCII 值存储。
- 每个十进制值都会自动转换为其 16 位二进制等效值并存储为十六进制数。
- 处理器使用小尾数字节排序。
- 负数将转换为其 2 的补码表示形式。
- 短浮点数和长浮点数分别使用 32 位或 64 位表示。
为未初始化数据分配存储空间
保留指令用于为未初始化的数据保留空间。
保留指令有五种基本形式:
| 指令 | 用途 |
|---|---|
| RESB | 保留Byte |
| RESW | 保留Word |
| RESD | 保留Doubleword |
| RESQ | 保留Quadword |
| REST | 保留十个字节 |
多重定义
一个程序中可以有多个数据定义语句。
例如
1 | choice DB 'Y' ;ASCII of y = 79H |
汇编器为多个变量定义分配连续的内存。
多次初始化
TIMES 指令允许对同一值进行多次初始化。 例如,可以使用以下语句定义一个名为marks、大小为 9 的数组并将其初始化为零。
1 | marks TIMES 9 DW 0 |
常量
NASM 提供了几个定义常量的指令。 我们已经在前面的章节中使用过 EQU 指令。
本节指出三个指令:
- EQU
- %assign
- %define
EQU指令
EQU指令用于定义常量,语法如下:
1 | CONSTANT_NAME EQU expression |
例如:
1 | TOTAL_STUDENTS equ 50 |
%assign指令
%assign 指令可用于定义数字常量,如 EQU 指令, 该指令允许重新定义。
例如:
1 | %assign TOTAL 10 |
该指令区分大小写。
%define
%define指令允许定义数字和字符串常量。 该指令类似于 C 中的#define。
例如,您可以将常量 PTR 定义为
1 | %define PTR [EBP+4] |
以上代码将_PTR_替换为[EBP+4]。
该指令还允许重新定义并且区分大小写。
算数指令
INC指令
用于将操作数加一。语法如下:
1 | INC destination |
DEC指令
用于将操作数减一。语法如下:
1 | DEC destination |
ADD和SUB指令
ADD和SUB指令用于执行字节、字和双字大小的二进制数据的简单加法/减法,即分别用于8位、16位或32位操作数的加或减。语法如下:
1 | ADD/SUB destination, source |
ADD/SUB 指令可以发生在 −
- Register to register
- Memory to register
- Register to memory
- Register to constant data
- Memory to constant data
但是,与其他指令一样,无法使用 ADD/SUB 指令进行内存到内存操作。 ADD 或 SUB 操作设置或清除溢出和进位标志。
MUL/IMUL指令
有两条指令用于将二进制数据相乘。 MUL(乘法)指令处理无符号数据,IMUL(整数乘法)指令处理有符号数据。 这两条指令都会影响进位和溢出标志。语法如下:
1 | MUL/IMUL multiplier |
两种情况下的被乘数都将位于累加器中,具体取决于被乘数和乘数的大小,并且生成的乘积也取决于操作数的大小存储在两个寄存器中。 以下部分解释了三种不同情况下的 MUL 指令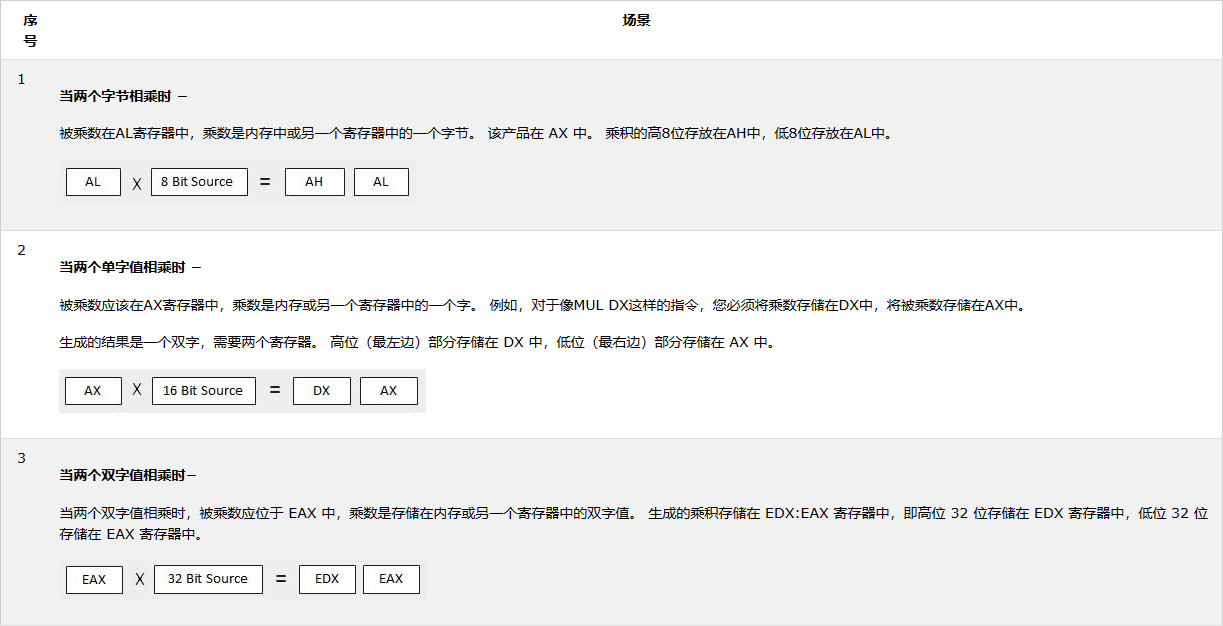
代码示例:
1 | section .text |
DIV/IDIV 指令
与MUL/IMUL类似
![[DIV_IDIV指令.png]]
代码示例:
1 | section .text |
